Web Audio提供了一个强大的音频处理系统,在我们现有的业务场景中,很少有使用到Web Audio,很多时候用到也仅限于播放一段音频。
除此之外,还能实现丰富的功能,比如:可视化、音色合成器、动态混音、声音特效、3D空间音频、均衡器、环境混响等,可以应用在音乐播放器、电子音乐软件、游戏音效、音乐游戏、直播互动等领域。
这篇文章是我在学习Web Audio的过程中写的一些总结和Demo,简单介绍一些API基础用法。
文章中所有示例:https://web-audio.johnsonlee.site/
AudioContext
AudioContext为音频处理提供一个上下文环境,相当于一个中央控制器,控制着音频路由图中的各个音频模块。
在开始音频处理之前,都需要创建一个AudioContext实例,并且可以全局共享同一个。所有(相关)的音频节点都需要包含在同一个AudioContext中,每个音频节点,只能关联一个AudioContext。
音频节点
音频节点即AudioNode,它是一个基类,作为一个音频路由图中的基本单位,它的工作依赖于AudioContext。
音频节点拥有自己的输入/输出,可以通过connect方法将一个节点的输出连接至另一个节点的输入。比如我们可以将一个音频节点连接至audioContext.destination节点来进行音频播放。
audioBufferSourceNode.connect(audioContext.destination)
上面的audioContext.destination是音频节点中的一种,音频节点可以分为三类:
- Source Node:能产生音频的节点,只有输出,没有输入。
- Process Node:对音频进行处理的节点,有输入(可能有多个)和输出。
- Destination Node:通常为音频播放设备,如扬声器。
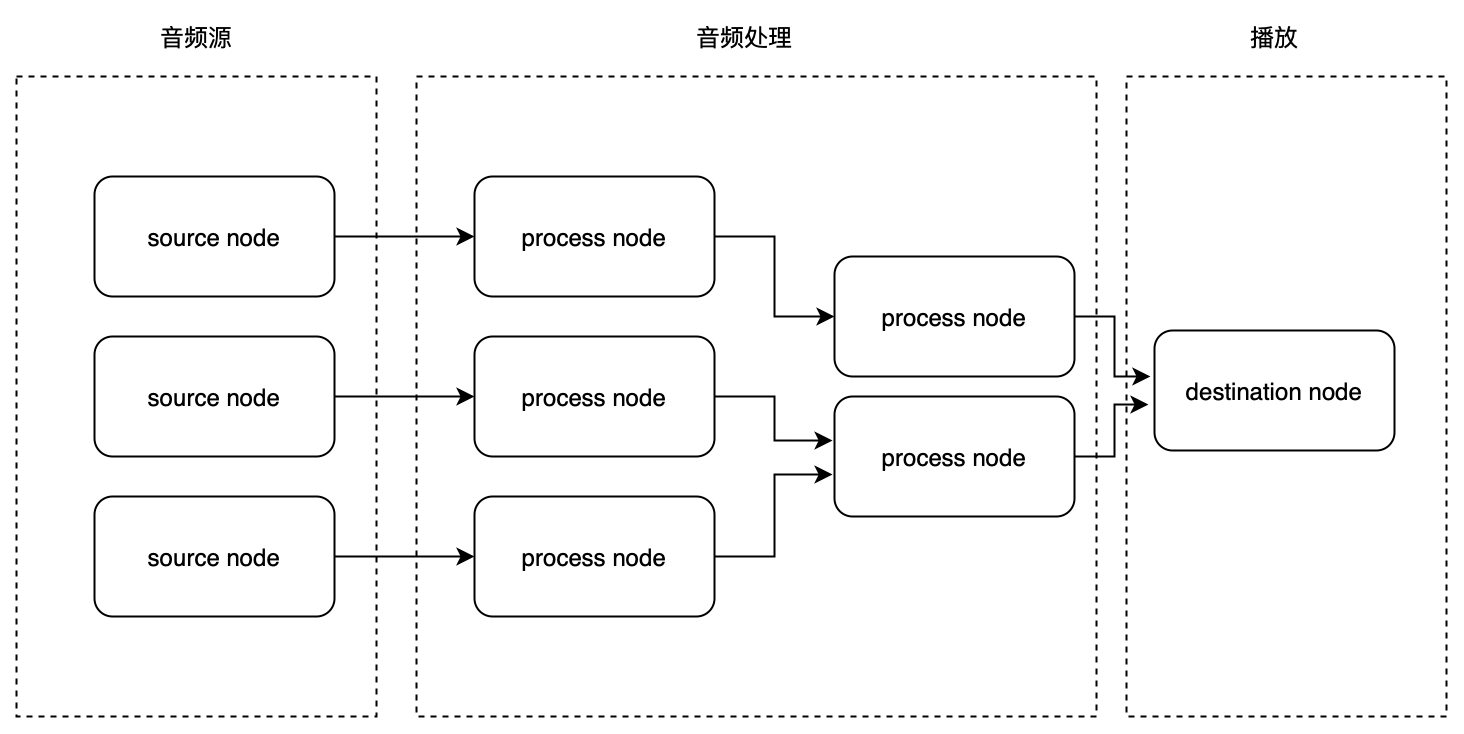
有的音频处理节点会有多个输出,比如ChannelSplitterNode,可以将音频拆分为多个声道,对应的,也有一个合并声道的节点ChannelMergerNode,有多个输入和一个输出。
路由图
Web Audio 提供的是模块化的API,在AudioContext中,各个音频节点的连接,构建了一个路由图,audioContext控制着整个路由图的运转。比如下面一个简单的音频播放示例
const ac = new AudioContext()
const $audio = document.querySelector('#audio');
const sourceNode = ac.createMediaElementSource($audio); // 从audio标签创建一个音频源节点
const gainNode = ac.createGain(); // 创建一个增益节点
gainNode.gain.value = 0; // 将增益设置为0(相当于音量设置为0)
$audio.addEventListener('play', () => {
gainNode.gain.exponentialRampToValueAtTime(1, 1); // 在1秒的时间内指数增长到1,实现一个播放渐入效果
});
sourceNode.connect(gainNode); // 音频源节点连接到增益节点
gainNode.connect(ac.destination); // 增益节点连接到destination进行播放
音频源
web中音频源包括:
- audio节点
- 网络加载的音频文件
- 实时音频流(webRTC、麦克风)
- 能产生音频信号的音频节点(如:OscillatorNode)
从标签加载音频源
网络加载的音频文件,需要将其转换成音频源节点,才能连接到路由图中,比如我们经常使用的<audio>标签,它是不能直接连接到其它音频节点的
const ac = new AudioContext();
const $audio = document.querySelector('#audio');
// create a source node from an audio
const sourceNode = ac.createMediaElementSource($audio);
sourceNode.connect(/* other audio node */);
使用http请求加载音频数据
我们也可以使用http请求,将二进制的音频数据下载到本地后,再创建一个音频源节点
const ac = new AudioContext();
const source = ac.createBufferSource();
source.connect(ac.destination);
fetch('xxx.mp3').then(res => res.arrayBuffer()).then(
async buffer => {
source.buffer = await ac.decodeAudioData(buffer);
source.start();
}
);
上面代码中,我们将解码后的数据(AudioBuffer)加载到了source.buffer属性中,实际上,这里除了从网络/本地加载音频文件外,我们也可以自己创建一个buffer丢给source.buffer来制造一些声音,比如下面的这个示例,使用随机函数生成一个白噪声音频
❗️
AudioBuffer的设计是为了存储短时间的音频片段,不建议将特别长的音频通过BufferSource方式进行播放,更推荐使用上一种方案。
使用内置振荡器产生声音
OscillatorNode是一个振荡器节点,它可以产生一个周期信号,可以指定type为square, sine, sawtooth, triangle, custom, 默认为sine。其次需要设置frequency属性来设定频率,它是[AudioParam](https://developer.mozilla.org/en-US/docs/Web/API/AudioParam)类型,不能直接赋值。
const ac = new AudioContext();
const oscillator = ac.createOscillator();
oscillator.type = 'square';
oscillator.frequency.value = 440; // 不能直接给frequency负值,可以设置其value
// oscillator.frequency.exponentialRampToValueAtTime(440, 1) // 也可以通过它提供的方法来设置
oscillator.connect(ac.destination);
oscillator.start();
注意到type还有一个值custom,我们可以自定义波形(决定声音的音色),Web Audio提供了一个接口PeriodicWave来创建一个周期波形。需要注意的是不能直接设置type为custom,而是要通过_setPeriodicWave_方法来设置自定义波形。
const real = [0, 0, 1, 0, 1]; // cosine terms
const imag = [0, 0, 0, 0, 0]; // sine terms
const periodicWave = ac.createPeriodicWave(real, imag);
oscillator.setPeriodicWave(periodicWave);
音频流
音频流也可以用来创建一个音频源节点,常见的音频流由麦克风、WebRTC产生,通过audioContext.createMediaStreamSource()方法从音频流创建一个音频源节点。
将将其连接到前面的示波器组件,便可以做一个简单的录音可视化效果,查看示例。
音频处理
音频分析处理相关的API,都可以归类音频处理节点,相关的API有很多,这里分别介绍几个常用API。
Analyse
AnalyserNode可以对音频信号进行实时的快速傅立叶变换(FFT)得到音频的时域/频域数据,拿到时域/频域的数据后,可以实现时域分析、频域分析、音频可视化动效等。
通过audioContext.createAnalyser()方法来创建一个AnalyserNode,创建之后可以设置一个fftSize属性,该属性指定要进行FFT的采样数据的窗口大小,它的值必须是2的非零整数倍,默认为2048。
const analyser = audioContext.createAnalyser();
analyser.fftSize = 2048;
const dataArray = new Uint8Array(analyser.frequencyBinCount);
analyser.getByteTimeDomainData(dataArray);
// analyser.getByteFrequencyData(dataArray);
analyser.frequencyBinCount是时域/频域数据的长度,它是fftSize的一半(因为实时音频信号的傅立叶变换具有对称性,只需要获取一半数据即可),通过analyser.getByteTimeDomainData(dataArray)方法将数据填充到8位无符号整型数组中。
之后,我们就可以使用dataArray进行对应的操作。可以使用上面的示波器组件来绘制一首音乐的波形:
将上面的绘制频谱图代码稍作修改,就可以做一个简单的音乐播放动效。
BiquadFilter
BiquadFilterNode是个双二阶数字滤波器。滤波器的作用是对特定频率的输入信号进行增强/减弱,通常用来控制音调、做均衡器。可以通过audioContext.createBiquadFilter()方法创建一个双二阶滤波器,它有4个关键的参数:type, frequency, Q, gain。
const filter = ac.createBiquadFilter();
filter.type = 'peaking'; // 设置类型为峰值滤波器
filter.Q.value = 1; // 峰值滤波器的带宽
filter.frequency.value = 1000; // 中心频率
filter.gain.value = 5; // 增益,单位db
// ...
source.connect(filter);
filter.connect(ac);
不同类型的滤波器在用法和效果上都有一定的差异,这里以低架滤波器、峰值滤波器、高架滤波器为例写了一个均衡器Demo。
下表列出了所有的滤波器类型及对应的参数说明:
| 类型 | 描述 | frequency | Q | gain |
|---|---|---|---|---|
| lowpass | 低通滤波器,只允许低于设定的值的频率通过 | 截止频率 | 值越小减弱越强 | 没用 |
| highpass | 高通滤波器,只允许高于设定的值的频率通过 | 截止频率 | 值越小减弱越强 | 没用 |
| bandpass | 带通滤波器,允许指定范围内的频率通过 | 中心频率 | 控制带宽,值越小带宽越大 | 没用 |
| lowshelf | 低架滤波器,对低于设定值的频率进行增强/减弱,高于的部分不变 | 上限频率 | 没用 | 正值增强,负值减弱,单位db |
| highshelf | 高架滤波器,对高于设定值的频率进行增强/减弱,低于的部分不变 | 下限频率 | 没用 | 正值增强,负值减弱,单位db |
| peaking | 峰值滤波器,在设定范围内的频率会被增强/减弱,其它部分不变 | 中心频率 | 控制带宽,值越小带宽越大 | 正值增强,负值减弱,单位db |
| notch | 陷波滤波器,也称作带阻滤波器,它的作用和带通滤波器相反 | 中心频率 | 控制带宽,值越小带宽越大 | 没用 |
| allpass | 全通滤波器,不会对输入信号进行增强/减弱,但是可以改变输入信号的相位,可以用来做延迟 | 群延迟最大频率,即发生相变的中心频率。 | 控制中频过渡的锐度,值越大过渡锐度越大 | 没用 |
Panner
PannerNode提供了3D空间音频能力(前提是播放设备必须拥有2个或以上的声道)。声音源在人的不同方向,听到的声音感受都是不一样的,甚至在声音源移动的时候由于多普勒效应会产生一种奇怪的声音。
而通常使用电子设备播放音乐的时候仅仅是简单的播放,PannerNode便为我们提供了模拟现实场景的能力,能够开发出具有真实听觉体验的VR、游戏等场景。
PannerNode工作在右手笛卡尔坐标系中,由位置坐标、朝向向量坐标确定其位置,声音呈锥形向空间扩散。可以通过设置coneInnerAngle属性控制声源扩散锥形的角度。

使用audioContext.createPanner()可以创建一个panner节点,它有几个关键的属性:
- positionX/positionY/positionZ:声源位置坐标
- orientationX/orientationY/orientationZ:声源朝向向量
- coneInnerAngle:锥形角度
- rolloffFactor:声音随距离的衰减速度
- distanceModel:声音衰减算法模型
音频空间化还需要使用到一个AudioListener,它表示的是空间中收听音频的人。在一个音频上下文中,仅有一个AudioListener,并且它不是AudioNode的子类,通过audioContext.listener获取到。
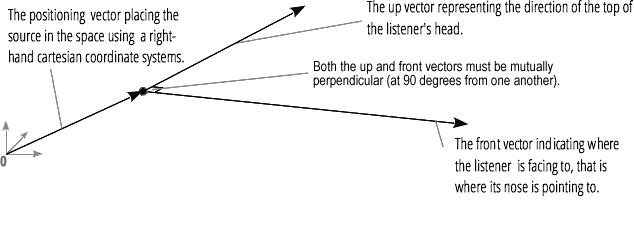
AudioListener也拥有几个类似的属性:
- forwardX/forwardY/forwardZ:收听者面部朝向向量
- upX/upY/upZ:收听者头部向量
- positionX/positionY/positionZ:收听者在空间中的坐标
了解了这些API,就可以开始写一个音频空间化效果了。
const panner = ac.createPanner();
panner.panningModel = 'HRTF'; // 音频空间化算法模型
panner.distanceModel = 'inverse'; // 远离时的音量衰减算法
panner.maxDistance = 500; // 最大距离
panner.refDistance = 50; // 开始衰减的参考距离
panner.rolloffFactor = 1; // 衰减速度
panner.coneInnerAngle = 360; // 声音360度扩散
panner.orientationX.value = 0; // 声源朝向x分量
panner.orientationY.value = 0;
panner.orientationZ.value = 1;
const listener = ac.listener;
listener.forwardX.value = 0; // 收听者面部朝向向量
listener.forwardY.value = 0;
listener.forwardZ.value = -1; // 设置与panner朝向相反,即与panner面对面
listener.upX.value = 0; // 收听着头部朝向向量
listener.upY.value = 1;
listener.upZ.value = 0;
source.connect(panner);
panner.connect(ac.destination);
播放过程中动态的设置panner和listener的position,即可实现空间化的效果,查看Demo。
Convolver
ConvolverNode可以对音频信号进行线性卷积运算,将特定的脉冲信号与音频进行卷积运算后,可以获得一些畸变效果,可以用来做一些环境混响效果。
ConvolverNode使用比较简单,通过audioContext.createConvolver()创建一个卷积器节点,它有两个属性:
- buffer:AudioBuffer类型,一个冲激信号(必须是.wav格式的文件)
- normalize:决定是否对buffer的冲激响应进行等功率的归一化缩放
normalize可能不是很好理解,有兴趣的同学可以深入学习,这里简单写个示例代码
const impulse = ac.decodeAudioData(arrayBuffer); // 解码加载好的冲激信号
const convolver = ac.createConvolver();
convolver.buffer = impulse;
source.connect(convolver);
convolver.connect(ac.destination);
这个API在使用上很简单,也不要求必须了解相关的理论基础,只需要找到对应的冲激信号文件。当然,在进行卷积运算后输出的音频功率会有所变化,一般情况需要配合GainNode来调节增益。
兼容性
Web Audio目前兼容性还不够完善,可以查看MDN兼容性表格,在复杂的应用场景中可能会遇到一些难以解决的问题。
结束语
Web Audio覆盖的内容很多,本文简单介绍了一些特性。
因为还在学习中,本文会继续更新完善。有兴趣的同学可以一起交流。
参考资料
Web Audio API - Web APIs | MDN
The ‘Mixing Secrets’ Free Multitrack Download Library
GitHub - GoogleChromeLabs/web-audio-samples: Web Audio API samples by Chrome Web Audio Team